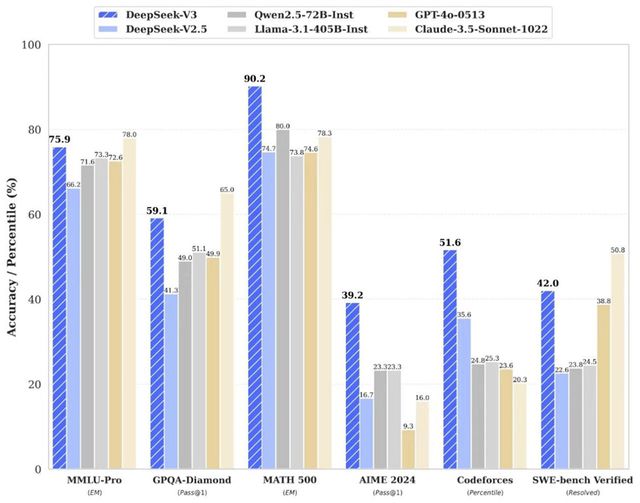
“DeepSeek-V3逾越了迄今为止全部开源模子。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。 12月26日,深度求索官方微信公众号推文称,旗下全新系列模子DeepSeek-V3首个版本上线并同步开源。 公众号推文是如许形貌的:DeepSeek-V3为自研MoE模子,671B参数,激活37B,在14.8T token上举行了预练习。DeepSeek-V3多项评测结果逾越了Qwen2.5-72B和Llama-3.1-405B等其他开源模子,并在性能上和天下顶尖的闭源模子GPT-4o以及Claude-3.5-Sonnet不分伯仲。
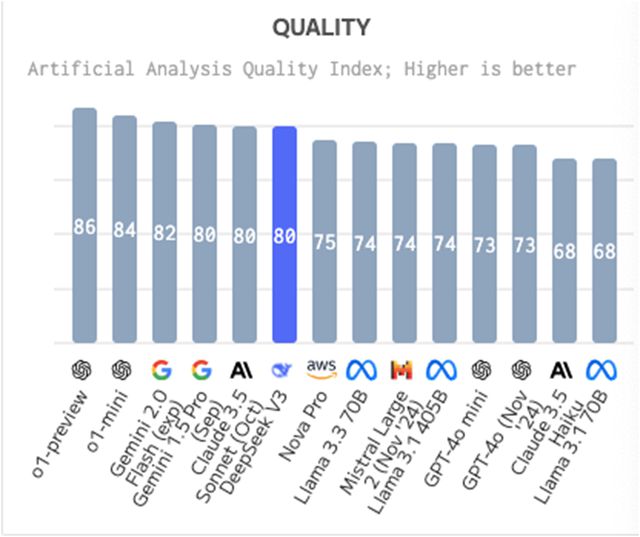
图片泉源:深度求索微信公众号 不外,广发证券发布的测试效果表现,DeepSeek-V3总体本领与其他大模子相称,但在逻辑推理和代码天生范畴具有自身特点。 更紧张的是,深度求索利用英伟达H800 GPU在短短两个月内就练习出了DeepSeek-V3,仅耗费了约558万美元。其练习费用相比GPT-4等大模子要少得多,据外媒估计,Meta的大模子Llama-3.1的练习投资凌驾了5亿美元。 消息一出,引发了外洋AI圈热议。OpenAI首创成员Karpathy乃至对此歌颂道:“DeepSeek-V3让在有限算力预算上举行模子预练习这件变乱得轻易。DeepSeek-V3看起来比Llama-3-405B更强,练习斲丧的算力却仅为后者的1/11。” 然而,在利用过程中,《逐日经济消息》记者发现,DeepSeek-V3竟然声称本身是ChatGPT。一时间,“DeepSeek-V3是否在利用ChatGPT输出内容举行练习”的质疑声四起。 对此,《逐日经济消息》记者采访了呆板学习奠定人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表现对全新的DeepSeek模子的细节还相识不敷,无法给出确切的答案。“但从广泛环境来说,险些全部的大模子都重要基于公开数据举行练习,因此没有特殊必要合成的数据。这些模子都是通过细致选择和清算练习数据(比方,专注于高质量泉源的数据)来取得改进。” 每经记者向深度求索公司发出采访哀求,停止发稿,尚未收到复兴。 国外独立评测机构:DeepSeek-V3逾越了迄今为止全部开源模子 针对DeepSeek-V3,独立评测网站Artificial Anlaysis就关键指标——包罗质量、代价、性能(每秒天生的Token数以及首个Token天生时间)、上下文窗口等多方面——与其他人工智能模子举行对比,终极得出以下结论。 质量:DeepSeek-V3质量高于均匀程度,各项评估得出的质量指数为80。
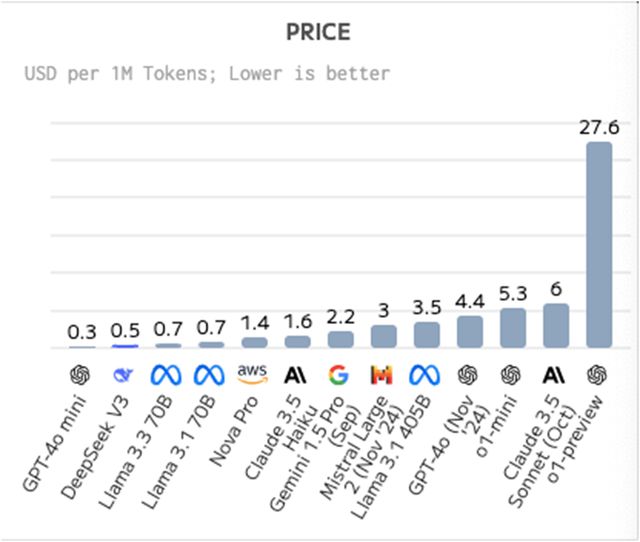
图片泉源:Artificial Anlaysis 代价:DeepSeek-V3比均匀代价更自制,每100万个Token的代价为0.48美元。此中,输入Token代价为每100万个Token 0.27美元,输出Token代价为每100万个Token1.10 美元。
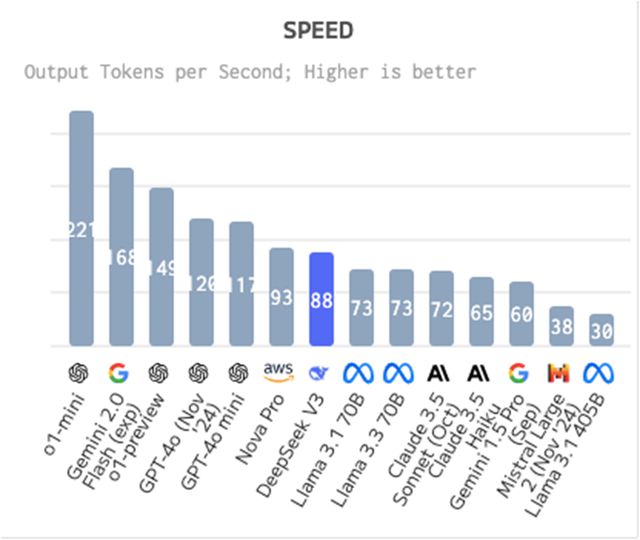
图片泉源:Artificial Anlaysis 速率:DeepSeek-V3比均匀速率慢,其输出速率为每秒87.5个Token。
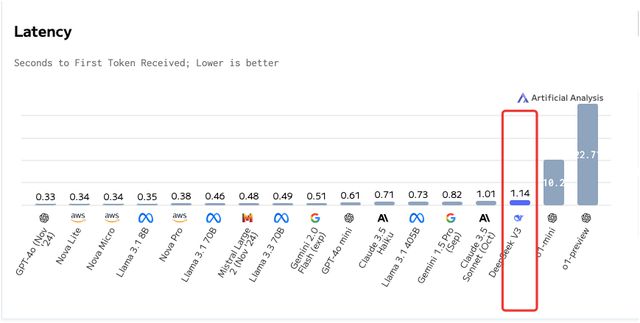
图片泉源:Artificial Anlaysis 耽误:DeepSeek-V3与均匀程度相比耽误更高,吸收首个Token(即首字相应时间)必要1.14秒。
图片泉源:Artificial Anlaysis 上下文窗口:DeepSeek-V3的上下文窗口比均匀程度小,其上下文窗口为13万个Token。 终极Artificial Anlaysis得出结论: “DeepSeek-V3模子逾越了迄今为止发布的全部开放权重模子,而且击败了OpenAI的GPT-4o(8月),并靠近Anthropic的Claude 3.5 Sonnet(10月)。 DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模子。现在唯一仍旧领先于DeepSeek的模子是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模子。领先于阿里巴巴的Qwen2.5 72B,DeepSeek如今是中国的AI领先者。” 广发证券:总体本领与其他大模子相称,逻辑推理和代码天生具有自身特点 12月29日广发证券盘算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的本领,昨们接纳了覆盖逻辑、数学、代码、文本等范畴的多个题目对模子举行测试,将其天生效果与豆包、Kimi以及通义千问大模子天生的效果举行比力。” 测试效果表现,DeepSeek-V3总体本领与其他大模子相称,但在逻辑推理和代码天生范畴具有自身特点。比方,在密文解码使命中,DeepSeek-V3是唯一给出精确答案的大模子;而在代码天生的使命中,DeepSeek-V3给出的代码解释、算法原理表明以及开辟流程的指引是最为全面的。在文本天生和数学盘算本领方面,DeepSeek-V3并未显现出显着优于其他大模子之处。 练习仅耗费558万美元,算力不紧张了? 除了本领,DeepSeek-V3最让业内惊奇的是它的低代价和低本钱。 《逐日经济消息》记者留意到,亚马逊Claude 3.5 Sonnet模子的API代价为每百万输入tokens 3美元、输出15美元。也就是说,即便是不按照优惠代价,DeepSeek-V3的利用费用也险些是Claude 3.5 Sonnet的五十三分之一。 相对低廉的代价,得益于DeepSeek-V3的练习本钱控制,深度求索在短短两个月内利用英伟达H800 GPU数据中央就练习出了DeepSeek-V3模子,耗费了约558万美元。其练习费用相比OpenAI的GPT-4等现在环球主流的大模子要少得多,据外媒估计,Meta的大模子Llama-3.1的练习投资凌驾了5亿美元。 DeepSeek“AI界拼多多”也由此得名。 DeepSeek-V3通过数据与算法层面的优化,大幅提拔算力使用服从,实现了协同效应。在大规模MoE模子的练习中,DeepSeek-V3接纳了高效的负载平衡计谋、FP8混淆精度练习框架以及通讯优化等一系列优化步伐,明显低落了练习本钱,以及通过优化MoE专家调理、引入冗余专家计谋、以及通过长上下文蒸馏提拔推理性能。这证实,模子结果不但依靠于算力投入,纵然在硬件资源有限的环境下,依托数据与算法层面的优化创新,仍旧可以高效使用算力,实现较好的模子结果。 广发证券分析称,DeepSeek-V3算力本钱低落的缘故原由有两点。 第一,DeepSeek-V3接纳的DeepSeekMoE是通过参考了各类练习方法后优化得到的,避开了行业内AI大模子练习过程中的各类题目。 第二,DeepSeek-V3接纳的MLA架构可以低落推理过程中的kv缓存开销,其练习方法在特定方向的选择也使得其算力本钱有所低落。 科技媒体Maginative的首创人兼主编Chris McKay对此批评称,对于人工智能行业来说,DeepSeek-V3代表了一种潜伏的范式变化,即大型语言模子的开辟方式。这一成绩表明,通过奇妙的工程和高效的练习方法,大概无需从前以为必须的巨大盘算资源,就能实现人工智能的前沿本领。 他还表现,DeepSeek-V3的乐成大概会促使人们重新评估人工智能模子开辟的既定方法。随着开源模子与闭源模子之间的差距不停缩小,公司大概必要在一个竞争日益猛烈的市场中重新评估他们的计谋和代价主张。 不外,广发证券分析师以为,算力依然是推动大模子发展的焦点驱动力。DeepSeek-V3的技能门路得到充实验证后,有望驱动相干AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到加强。尤其在现实应用中,推理过程涉及到对大量及时数据的快速处置惩罚和决议,仍旧必要强盛的算力支持。 DeepSeek-V3自称是ChatGPT,AI正在“污染”互联网? 在DeepSeek-V3刷屏之际,有一个bug也引发热议。 在试用DeepSeek-V3过程中,《逐日经济消息》记者在对话框中扣问“你是什么模子”时,它给出了一个令人惊奇的答复:“我是一个名为ChatGPT的AI语言模子,由OpenAl开辟。”别的,它还增补阐明,该模子是“基于GPT-4架构”。
图片泉源:每经记者试用DeepSeek-V3截图 国表里许多用户也都反映了这一征象。而且,12月27日,Sam Altman发了一个帖文,外媒指出,Altman这篇推文意在暗讽其竞争对手对OpenAI数据的发掘。
图片泉源:Sam Altman X账号推文 于是,有人就开始质疑:DeepSeek-V3是否是在ChatGPT的输出底子上练习的?为此,《逐日经济消息》向深度求索发出采访哀求。停止发稿,尚未收到复兴。 针对这种环境产生的缘故原由,每经记者采访了呆板学习奠定人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表现,他对全新的DeepSeek模子的细节还相识不敷,无法给出确切的答案。“但从广泛环境来说,险些全部的大模子都重要基于公开数据举行练习,因此没有特殊必要合成的数据。这些模子都是通过细致选择和清算练习数据(比方,专注于高质量泉源的数据)来取得了改进。” TechCrunch则推测称,深度求索大概用了包罗GPT-4通过ChatGPT天生的文本的公共数据集。“假如DeepSeek-V3是用这些数据举行练习的,那么该模子大概已经记着了GPT-4的一些输出,如今正在逐字反刍它们。” “显然,该模子(DeepSeek-V3)大概在某些时间看到了ChatGPT的原始反应,但现在尚不清晰从那里看到的,”伦敦国王学院专门研究人工智能的研究员Mike Cook也指出,“这也大概是个‘不测’。”他进一步表明称,根据竞争对手AI体系输出练习模子的做法大概对模子质量产生“非常糟糕”的影响,由于它大概导致幻觉和误导性答案。 不外,DeepSeek-V3也并非是第一个错误辨认本身的模子,谷歌的Gemini等偶然也会声称是竞争模子。比方,Gemini在平凡话提示下称本身是百度的文心一言谈天呆板人。 造成这种环境的缘故原由大概在于,AI公司在互联网上获取大量练习数据,但是,现现在的互联网本就充斥着各种各样用AI生产出来的数据。据外媒估计,到2026年,90%的互联网数据将由AI天生。这种 “污染” 使得从练习数据会合彻底过滤AI输出变得相称困难。 “互联网数据如今充斥着AI输出,”非营利构造AI Now Institute的首席AI科学家Khlaaf表现,基于此,假如DeepSeek部门利用了OpenAI模子举行提炼数据,也不敷为奇。 |