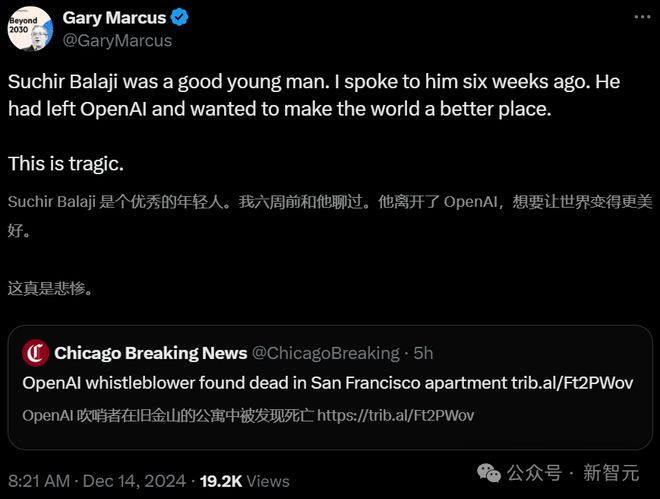
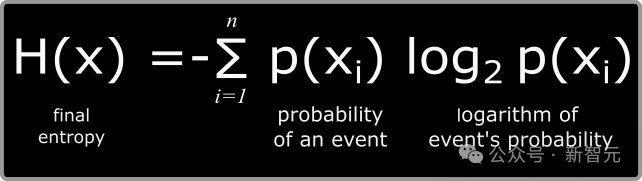新智元报道 编辑:Aeneas 好困 【新智元导读】26岁的OpenAI吹哨人,在发出公开控告不到三个月,被发现死在本身的公寓中。法医认定,死由于自尽。那么,他在死前两个月发表的一篇博文中,都说了什么? 就在刚刚,消息曝出:OpenAI吹哨人,在家中离世。 曾在OpenAI工作四年,控告公司侵占版权的Suchir Balaji,上月尾在旧金山公寓中被发现殒命,年仅26岁。 旧金山警方表现,11月26日下战书1时许,他们接到了一通要求检察Balaji安危的电话,但在到达后却发现他已经殒命。
这位吹哨人手中把握的信息,本来将在针对OpenAI的诉讼中发挥关键作用。 现在,他却不测去世。 法医办公室认定,死由于自尽。警方也表现,「并未发现任何他杀证据」。
他的X上的末了一篇帖子,正是先容本身对于OpenAI练习ChatGPT是否违背法律的思索和分析。 他也夸大,盼望这不要被解读为对ChatGPT或OpenAI自己的品评。
现在,在这篇帖子下,网友们纷纷发出哀悼。
Suchir Blaji的朋侪也表现,他人非常智慧,绝不像是会自尽的人。 吹哨人告诫:OpenAI练习模子时违背原则 Suchir Balaji曾到场OpenAI到场开辟ChatGPT及底层模子的过程。 本年10月发表的一篇博文中他指出,公司在利用消息和其他网站的信息练习其AI模子时,违背了「公道利用」原则。
博文地点:https://suchir.net/fair_use.html 然而,就在公开控告OpenAI违背美国版权法三个月之后,他就离世了。
为什么11月尾的事变12月中旬才爆出来,网友们也表现质疑 实在,自从2022年底公开辟布ChatGPT以来,OpenAI就面对着来自作家、步伐员、记者等群体的一波又一波的诉讼潮。 他们以为,OpenAI非法利用本身受版权掩护的质料来练习AI模子,公司估值攀升至1500亿美元以上的果实,却本身独享。 本年10月23日,《纽约时报》发表了对Balaji的采访,他指出,OpenAI正在侵害那些数据被使用的企业和创业者的长处。 「假如你认同我的观点,你就必须脱离公司。这对整个互联网生态体系而言,都不是一个可连续的模式。」 一个抱负主义者之死 Balaji在加州长大,十几岁时,他发现了一则关于DeepMind让AI本身玩Atari游戏的报道,心生向往。 高中结业后的gap year,Balaji开始探索DeepMind背后的关键理念——神经网络数学体系。 Balaji本科就读于UC伯克利,主修盘算机科学。在大学期间,他信赖AI能为社会带来巨大益处,好比治愈疾病、延缓朽迈。在他看来,昨们可以创造某种科学家,来办理这类题目。
2020年,他和一批伯克利的结业生们,共同前去OpenAI工作。
然而,在参加OpenAI、担当两年研究员后,他的想法开始变化。
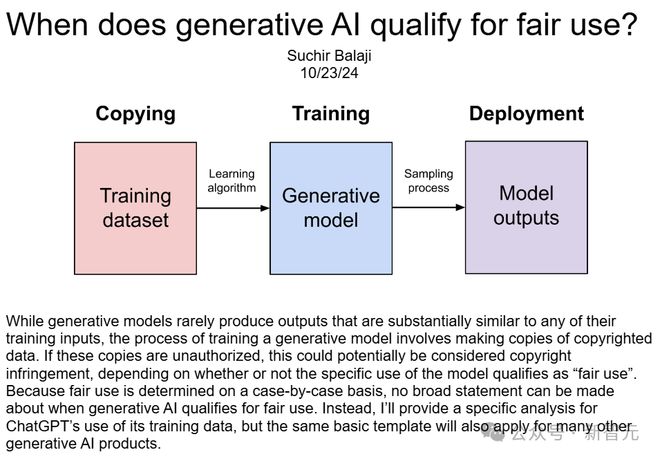
在那边,他被分配的使命是为GPT-4网络互联网数据,这个神经网络花了几个月的时间,分析了互联网上险些全部英语文本。 Balaji以为,这种做法违背了美国关于已发表作品的「公道利用」法律。本年10月尾,他在个人网站上发布一篇文章,论证了这一观点。 现在没有任何已知因素,可以或许支持「ChatGPT对其练习数据的利用是公道的」。但必要阐明的是,这些论点并非仅针对ChatGPT,雷同的叙述也实用于各个范畴的浩繁天生式AI产物。
根据《纽约时报》状师的说法,Balaji把握着「独特的相干文件」,在纽约时报对OpenAI的诉讼中,这些文件极为有利。 在预备取证前,纽约时报提到,至少12人(多为OpenAI的前任或现任员工)把握着对案件有资助的质料。 在已往一年中,OpenAI的估值已经翻了一倍,但消息机构以为,该公司和微软抄袭和盗用了本身的文章,严峻侵害了它们的贸易模式。 诉讼书指出—— 微软和OpenAI容易地攫取了记者、消息工作者、批评员、编辑等为地方报纸作出贡献的劳动结果——完全无视这些为地方社区提供消息的创作者和发布者的付出,更遑论他们的法律权利。 而对于这些控告,OpenAI予以果断否认。他们夸大,大模子练习中的全部工作,都符合「公道利用」法律规定。
为什么说ChatGPT没有「公道利用」数据 为什么OpenAI违背了「公道利用」法?Balaji在长篇博文中,列出了细致的分析。
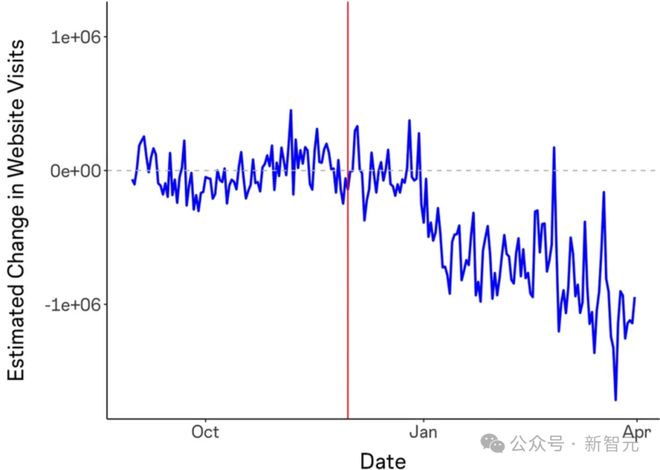
他引用了1976年《版权法》第107条中对「公道利用」的界说。 是否符合「公道利用」,应思量的因素包罗以下四条: (1)利用的目标和性子,包罗该利用是否具有贸易性子或是否用于非营利教诲目标;(2)受版权掩护作品的性子;(3)所利用部门相对于整个受版权掩护作品的数目和实质性;(4)该利用对受版权掩护作品的潜伏市场或代价的影响。 按(4)、(1)、(2)、(3)的次序,Balaji做了具体论证。 因素(4):对受版权掩护作品的潜伏市场影响 由于ChatGPT练习集对市场代价的影响,会因数据泉源而异,而且由于其练习集并未公开,这个题目无法直接答复。 不外,某些研究可以量化这个效果。 《天生式AI对在线知识社区的影响》发现,在ChatGPT发布后,Stack Overflow的访问量降落了约12%。
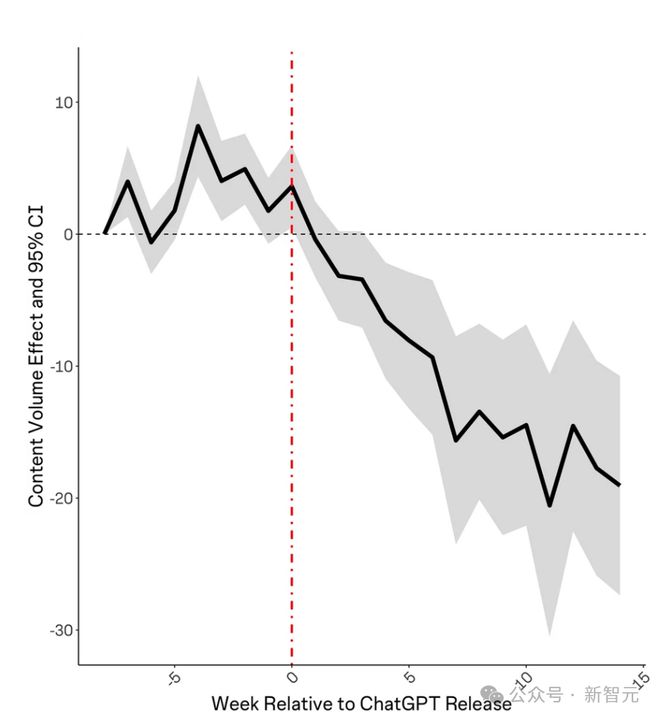
别的,ChatGPT发布后每个主题的提问数目也有所降落。
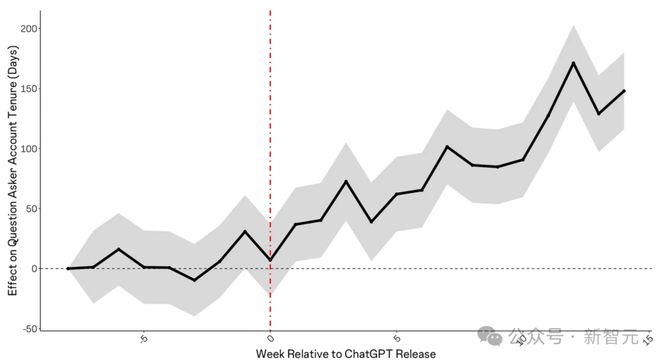
提问者的均匀账户年事也在ChatGPT发布后呈上升趋势,这表明新成员要么没有参加,要么正在脱离社区。
而Stack Overflow,显然不是唯一受ChatGPT影响的网站。比方,作业资助网站Chegg在陈诉ChatGPT影响其增长后,股价下跌了40%。
固然,OpenAI和谷歌如许的模子开辟商,也和Stack Overflow、Reddit、美联社、News Corp等签署了数据允许协议。 但签订了协议,数据就是「公道利用」吗? 总之,鉴于数据允许市场的存在,在未得到雷同允许协议的环境下利用受版权掩护的数据举行练习也构成了市场长处侵害,由于这剥夺了版权持有人的正当收入泉源。 因素(1):利用目标和性子,是贸易性子,照旧教诲目标 书评家可以在批评中引用某书的片断,固然这大概会侵害后者的市场代价,但仍被视为公道利用,这是由于,二者没有替换或竞争关系。 这种替换利用和非替换利用之间的区别,源自1841年的「Folsom诉Marsh案」,这是一个建立公道利用原则的里程碑案例。
题目来了——作为一款贸易产物,ChatGPT是否与用于练习它的数据具有相似的用途? 显然,在这个过程中,ChatGPT创造了与原始内容形成直接竞争的替换品。 好比,假如想知道「为什么在浮点数运算中,0.1+0. 2=0.30000000000000004?」这种编程题目,就可以直接向ChatGPT(左)提问,而不必再去搜刮Stack Overflow(右)。
因素(2):受版权掩护作品的性子 这一因素,是各项尺度中影响力最小的一个,因此不作具体讨论。 因素(3):利用部门相对于团体受掩护作品的数目及实质性 思量这一因素,可以有两种表明—— (1)模子的练习输入包罗了受版权掩护数据的完备副本,因此「利用量」现实上是整个受版权掩护作品。这倒霉于「公道利用」。 (2)模子的输出内容险些不会直接复制受版权掩护的数据,因此「利用量」可以视为靠近零。这种观点支持「公道利用」。 哪一种更符合实际? 为此,作者接纳信息论,对此举行了量化分析。 在信息论中,最根本的计量单元是比特,代表着一个是/否的二元选择。 在一个分布中,均匀信息量称为熵,同样以比特为单元(根据香农的研究,英文文本的熵值约在每个字符0.6至1.3比特之间)。
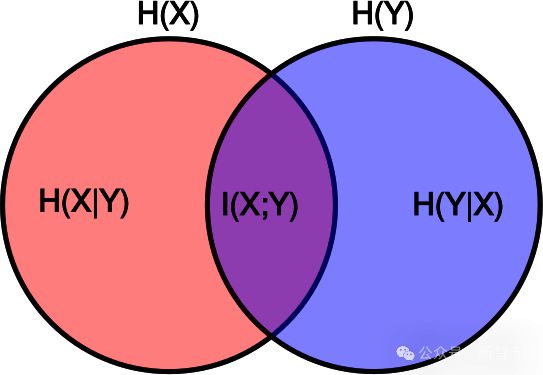
两个分布之间共享的信息量称为互信息(MI),其盘算公式为: 在公式中,X和Y表现随机变量,H(X)是X的边际熵,H(X|Y)是在已知Y的环境下X的条件熵。假如将X视为原创作品,Y视为其衍生作品,那么互信息I(X;Y)就表现创作Y时鉴戒了多少X中的信息。 对于因素3,重点关注的是互信息相对于原创作品信息量的比例,即相对互信息(RMI),界说如下: 此概念可用简朴的视觉模子来明白:假如用赤色圆圈代表原创作品中的信息,蓝色圆圈代表新作品中的信息,那么相对互信息就是两个圆圈重叠部门与赤色圆圈面积的比值:
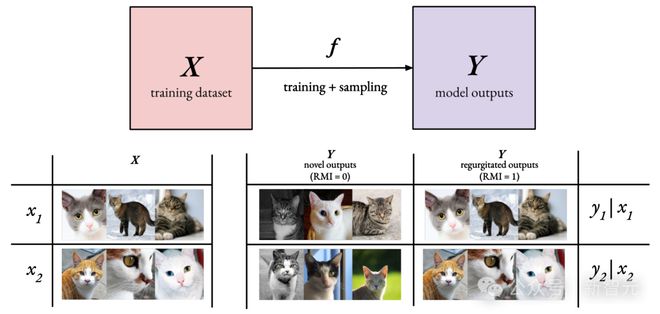
在天生式AI范畴中,重点关注相对互信息(RMI),此中X表现潜伏的练习数据集,Y表现模子天生的输出聚集,而f则代表模子的练习过程以及从天生模子中举行采样的过程:
在实践中,盘算H(Y|X)——即已练习天生模子输出的信息熵——相对轻易。但要估算H(Y)——即在全部大概练习数据集上的模子输出总体信息熵——则极其困难。 至于H(X)——练习数据分布的真实信息熵——固然盘算困难但还是可行的。 可以作出一个公道假设:H(Y) ≥ H(X)。 这个假设是有依据的,由于完善拟合练习分布的天生模子会出现H(Y) = H(X)的特性,同样,过分拟合而且影象练习数据的模子也是云云。 而对于欠拟合的天生模子,大概会引入额外的噪声,导致H(Y) > H(X)。在H(Y) ≥ H(X)的条件下,就可以为RMI确定一个下限: 这个下限背后的根本原理是:输出的信息熵越低,就越大概包罗来自模子练习数据的信息。 在极度环境下,就会导致「内容重复输出」的题目,即模子会以确定性的方式,输出练习数据中的片断。 纵然在非确定性的输出中,练习数据的信息仍大概以某种水平被利用——这些信息大概被分散融入到整个输出内容中,而不是简朴的直接复制。 从理论上讲,模子输出的信息熵并不必要低于原始数据的真实信息熵,但在现实开辟中,模子开辟者每每倾向于选择让输出熵更低的练习和摆设方法。 这重要是由于,熵值高的输出在采样过程中会包罗更多随机性,轻易导致内容缺乏连贯性或产生虚伪信息,也就是「幻觉」。 怎样低落信息熵? 数据重复征象 在模子练习过程中,让模子多次打仗同一数据样本是一种很常见的做法。 但假如重复次数过多,模子就会完备地记下这些数据样本,并在输出时简朴地重复这些内容。 举个例子,昨们先在莎士比亚作品集的部门内容上对GPT-2举行微调。然后用差别颜色来区分每个token的信息熵值,此中赤色表现较高的随机性,绿色表现较高简直定性。
当仅用数据样本练习一次时,模子对「First Citizen」(第一公民)这一提示的补全内容固然不敷连贯,但表现出高熵值和创新性。 然而,在重复练习十次后,模子完全记着了《科利奥兰纳斯》脚本的开头部门,并在吸收到提示后机器地重复这些内容。 在重复练习五次时,模子体现出一种介于简朴重复和创造性天生之间的状态——输出内容中既有新创作的部门,也有影象的内容。 假设英语文本的真实熵值约为每字符0.95比特,那么这些输出中就有约莫 的内容是来自练习数据集。 强化学习机制 ChatGPT产生低熵输出的重要缘故原由在于,它接纳了强化学习举行后练习——特殊是基于人类反馈的强化学习(RLHF)。 RLHF倾向于低落模子的熵值,由于其重要目的之一是低落「幻觉」的发生率,而这种「幻觉」通常源于采样过程中的随机性。 理论上,一个熵值为零的模子可以完全制止「幻觉」,但如许的模子现实上就酿成了练习数据集的简朴检索工具,而非真正的天生模子。 下面是几个向ChatGPT提出查询的示例,以及对应输出token的熵值:
根据 ,可以估计这些输出中约有73%到94%的内容,对应于练习数据会合的信息。 假如思量RLHF的影响(导致 ),这个估计值大概偏高,但熵值与练习数据利用量之间的相干性依然非常显着。 比方,纵然不相识ChatGPT的练习数据集,昨们也会发现它讲的笑话满是靠影象,由于这些内容险些都是以确定性方式天生的。 这种分析方法固然比力大略,但它展现了练习数据会合的版权内容怎样影响模子输出。 但更紧张的是,这种影响非常深远。纵然是对因素(3)做出更宽松的表明,也难以支持「公道利用」的主张。 终极,Suchir Balaji得出结论:从这4个因向来看,它们险些都不支持「ChatGPT在公道利用练习数据」。 10月23日,Balaji发出这篇博客。 一个月后,他死于本身的公寓。 参考资料: https://www.mercurynews.com/2024/12/13/openai-whistleblower-found-dead-in-san-francisco-apartment/?noamp=mobile https://suchir.net/fair_use.html |