AIxiv专栏是呆板之心发布学术、技能内容的栏目。已往数年,呆板之心AIxiv专栏吸收报道了2000多篇内容,覆盖环球各大高校与企业的顶级实行室,有用促进了学术交换与流传。假如您有良好的工作想要分享,接待投稿大概接洽报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com 想象如许一个场景:你正在暖锅店和朋侪畅聊,一个呆板人纯熟地为你倒饮料、端菜,完全不必要你分心招呼服务员。这个听起来像科幻的场景,已经被清华大学交织信息院的研究者们酿成了实际!他们发现了具身智能范畴的 “圣杯”——data scaling laws,让呆板人实现了真正的零样本泛化,可以无需任何微调就能泛化到全新的场景和物体。这一突破性发现,很大概成为呆板人范畴的 “ChatGPT 时候”,彻底改变昨们开辟通用呆板人的方式!
视频链接:https://mp.weixin.qq.com/s/hJjE_C3KMn7gKjIvfXMhGg 从暖锅店到电梯,呆板人显现惊人泛化力 研究团队可不是只在实行室里玩玩具。他们把呆板人带到了各种真实场景:暖锅店、咖啡厅、公园、喷泉旁,乃至是电梯里。更令人震动的是,呆板人在这些前所未见的情况中都显现出了超强的顺应本领!
视频链接:https://mp.weixin.qq.com/s/hJjE_C3KMn7gKjIvfXMhGg 为了确保研究的可复现性,团队慷慨地开源了全部资源,包罗耗时半年网络的海量人类演示数据:
连 Google DeepMind 的呆板人专家 Ted Xiao 都不由得为这项研究点赞,称其对呆板人大模子期间具有里程碑意义!
Scaling Laws:从 ChatGPT 到呆板人的制胜法则 还记得 ChatGPT 为什么能横空出世吗?答案就是 scaling laws!如今,清华团队初次证实:这个法则在呆板人范畴同样实用。究竟上,真正的 scaling laws 包罗数据、模子和算力三个维度,而本研究重点突破了最底子也最关键的数据维度。
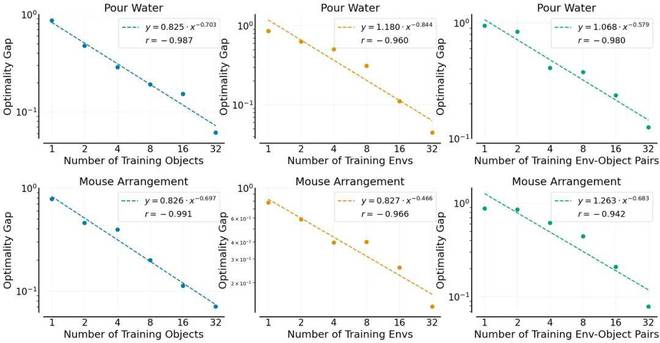
视频链接:https://mp.weixin.qq.com/s/hJjE_C3KMn7gKjIvfXMhGg 研究团队利用便携式手持夹爪 UMI,在真实情况中网络了凌驾 4 万条人类演示数据。他们接纳最新的 Diffusion Policy 方法从这些数据中学习呆板人控制模子,并通过惊人的 15000 + 次实机测试举行严谨评估,终极发现了三个革命性的幂律关系:
这意味着什么?简朴说:只要有充足的数据,呆板人就能像 ChatGPT 明白语言一样,天然地明白和顺应物理天下!这一发现不但证明了呆板人范畴与语言模子存在惊人的相似性,更为猜测数据规模与模子性能的关系提供了坚固的理论底子。 颠覆性发现:数据网络原来要这么做! 研究团队还破解了一个困扰业界的困难:对于给定的操纵使命,怎样优化选择情况数目、物体数目和每个物体的演示次数? 颠末大量实行,他们得出了两个出人料想的结论: 1. 当情况数目充足多时,在单一情况中网络多个差别的操纵物体的数据收益极其有限 —— 换句话说,每个情况只必要一个操纵物体的数据就够了。
2. 单个物体的演示数据很轻易到达饱和 —— 在倒水和摆放鼠标等使命中,总演示数据到达 800 次时,性能就开始趋于稳固。因此,每个物体 50 次树模根本就能搞定。
为验证这个计谋,团队找来 4 个人,只花了一个下战书就网络到了练习数据。效果令人震动:在 8 个全新场景中,呆板人乐成率高达 90%!这意味着,本来大概必要几个月的数据网络工作,如今大概只必要几天就能完成! 模子规模化探索的不测发现 除了数据规模,研究团队还在模子规模化方面有三个紧张发现:
将来预测 数据规模化正在推动呆板人技能走向新纪元。但研究团队提示:比起盲目增长数据量,提拔数据质量大概更为紧张。关键题目在于:
这些都是 Data Scaling Laws 研究正在积极探索的方向。信赖在不久的未来,具有超强顺应力的呆板人将走进千家万户,让科幻影戏中的场景变为实际!而这统统,都将从清华团队发现的这个底子性规律开始! 关于作者 该项目有两位共同一作。一位是清华大学交织信息研究院四年级博士生胡英东,专注于具身智能范畴的前沿研究。他致力于探索通用呆板人体系所面对的底子性题目,旨在使呆板人可以或许在各种非布局化的实际情况中泛化其学习到的举动。
另一位是交织信息研究院一年级博士生林凡淇。他专注于将大模子的先验知识融合到呆板人使命中,资助呆板人完成一样平常生存中的复杂使命;同时他盼望使用已有的呆板人算法、视觉语言大模子,探索呆板人落地的大概性。
项目标通讯作者是清华大学交织信息研究院的助理传授高阳,他重要研究盘算机视觉与呆板人学。此前,他在美国加州大学伯克利分校得到博士学位,师从 Trevor Darrell 传授。他还在加州伯克利大学与 Pieter Abbeel 等人互助完成了博士后工作。在此之前,高阳从清华大学盘算机系结业,与朱军传授在贝叶斯推理方面开展了研究工作。他在 2011-2012 年在谷歌研究院举行了天然语言处置惩罚相干的研究工作、2016 年在谷歌主动驾驶部分 Waymo 的相机感知团队工作,在 2018 年与 Vladlen Koltun 博士在英特尔研究院在端到端主动驾驶方面举行了研究工作。高阳在人工智能顶级集会 NeurIPS,ICML,CVPR,ECCV,ICLR 等发表过多篇学术论文,谷歌学术引用量凌驾 2000 次。
|